final-project-digitalskola
An end-to-end pipeline to convert raw CSV files into Parquet format, load them as external tables, and transform them into Google BigQuery data warehouse orchestrated with Apache Airflow.
View the Project on GitHub thomaspanji/final-project-digitalskola
Create a BigQuery Data Warehouse with Apache Airflow as a Workflow Orchestrator
Scope of Works
This is an individual project in Data Engineer bootcamp given by DigitalSkola to make an end-to-end pipeline to create a data warehouse on the cloud. All of the processes are running on Google Cloud Platform, specifically Google Cloud Storage, Google Composer, Google Dataproc, and Google BigQuery with a free tier usage.
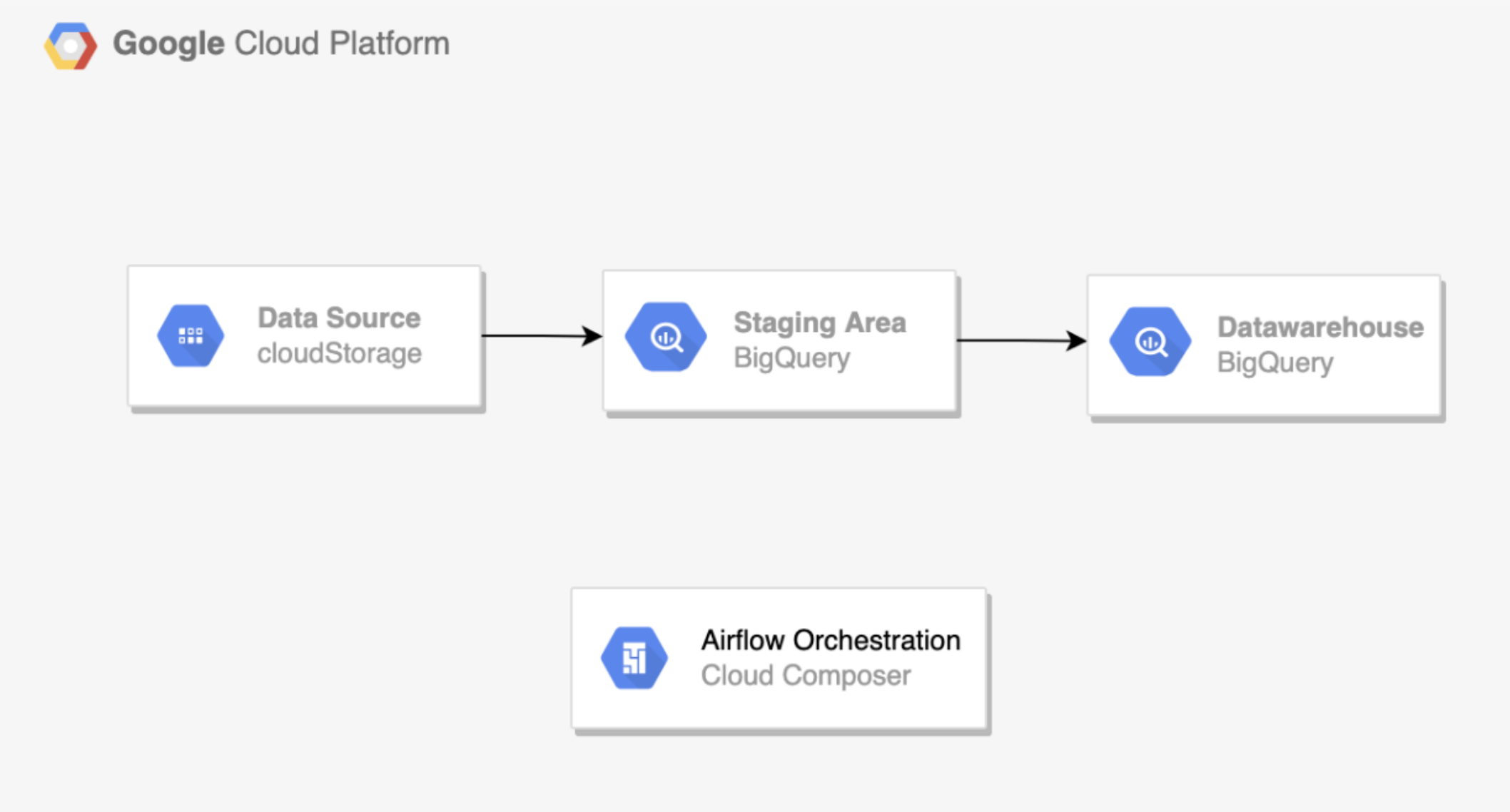
The project flow diagram is described in this picture.
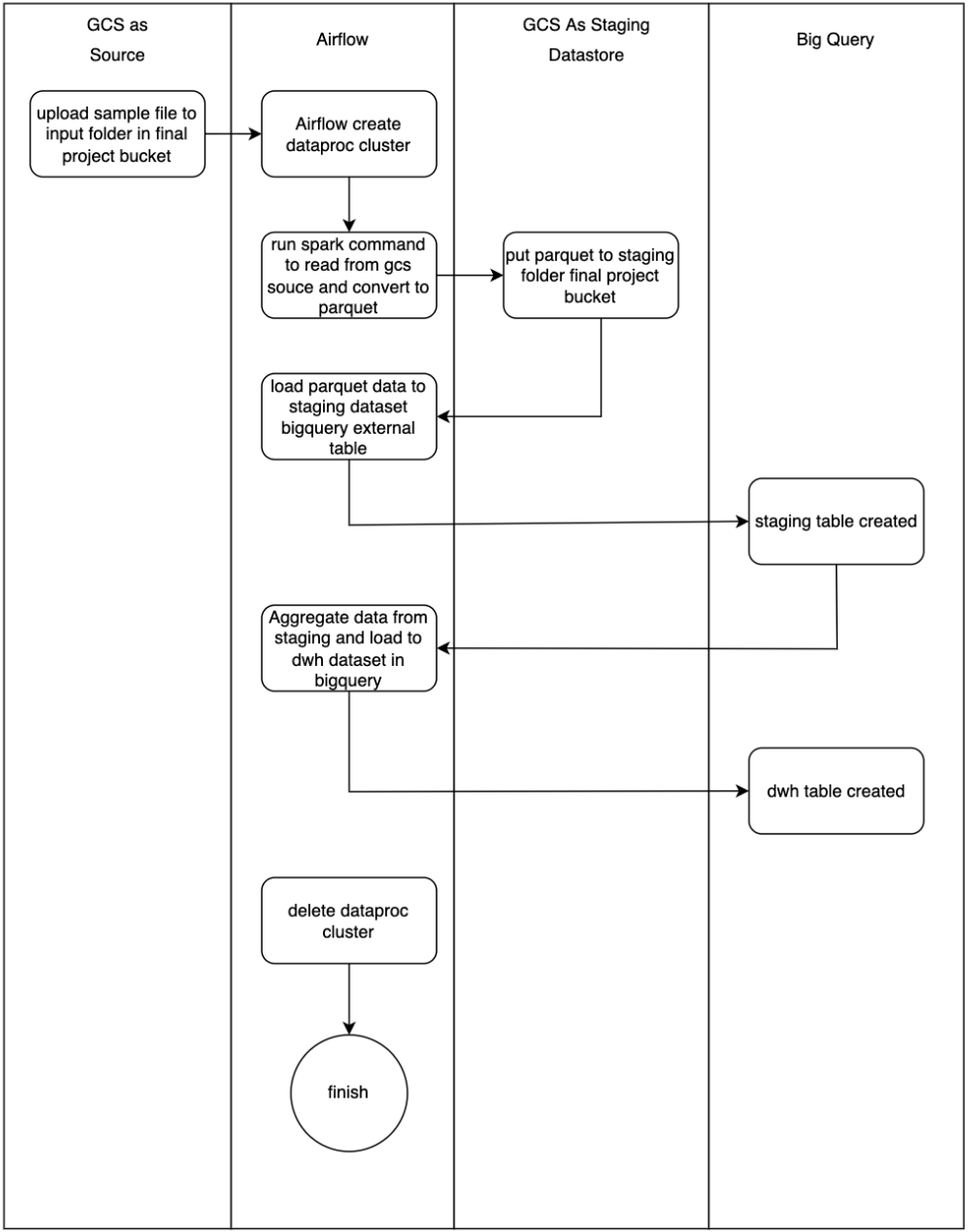
The main thing of this project is you process raw files and convert them into Parquet format, saved to a storage, then create external tables from that Parquet files which will be processed further to create data warehouse tables.
As seen in the diagram, we will be deploying an on-demand Dataproc cluster. We create it when we schedule to run a Spark application and delete it when execution is finished. Also, we need to create an external PySpark script to convert raw files into Parquet. The rest of our code will reside in Airflow’s main script.
Data
The data is provided in a ZIP file. We must extract and upload them into Google Cloud Storage. The data contains eight files, such as immigration data, port, states, airport codes, country, weather, and orders.
Google Cloud Storage
Google Cloud Storage is used to store our raw files, formatted in CSV. It is also used to store files in a staging area which has Parquet format. Apache Airflow from Google Composer also created some default folders to store our dags files, plugins, secret, and data just like when installing the tools on a local computer.
Google Dataproc
Google Dataproc is a managed Spark and Hadoop environment. We must create a cluster to activate the environment. In this project, we use an on-demand cluster just for processing a Spark application to convert CSV files to Parquet format. After the application has finished executing, the cluster will be deleted. Due to the use of the free tier, the resources provided are limited to project and regional quotas.
Google BigQuery
Google BigQuery is used to store external tables and create a data warehouse. External table means that we don’t put a real data in here but only create the schema from external sources. In this case, the Parquet files located in the Google Cloud Storage will be the source of our external tables.
We also run queries with tables sourced from the external tables to create a data warehouse. The queries include casting data types and aggregating data.
Google Composer
Google Composer is a fully managed workflow orchestration service built on Apache Airflow. Apache Airflow itself is a platform to programmatically author, schedule, and monitor workflows. It is an open-source tool and all built using Python program.
Apache Airflow
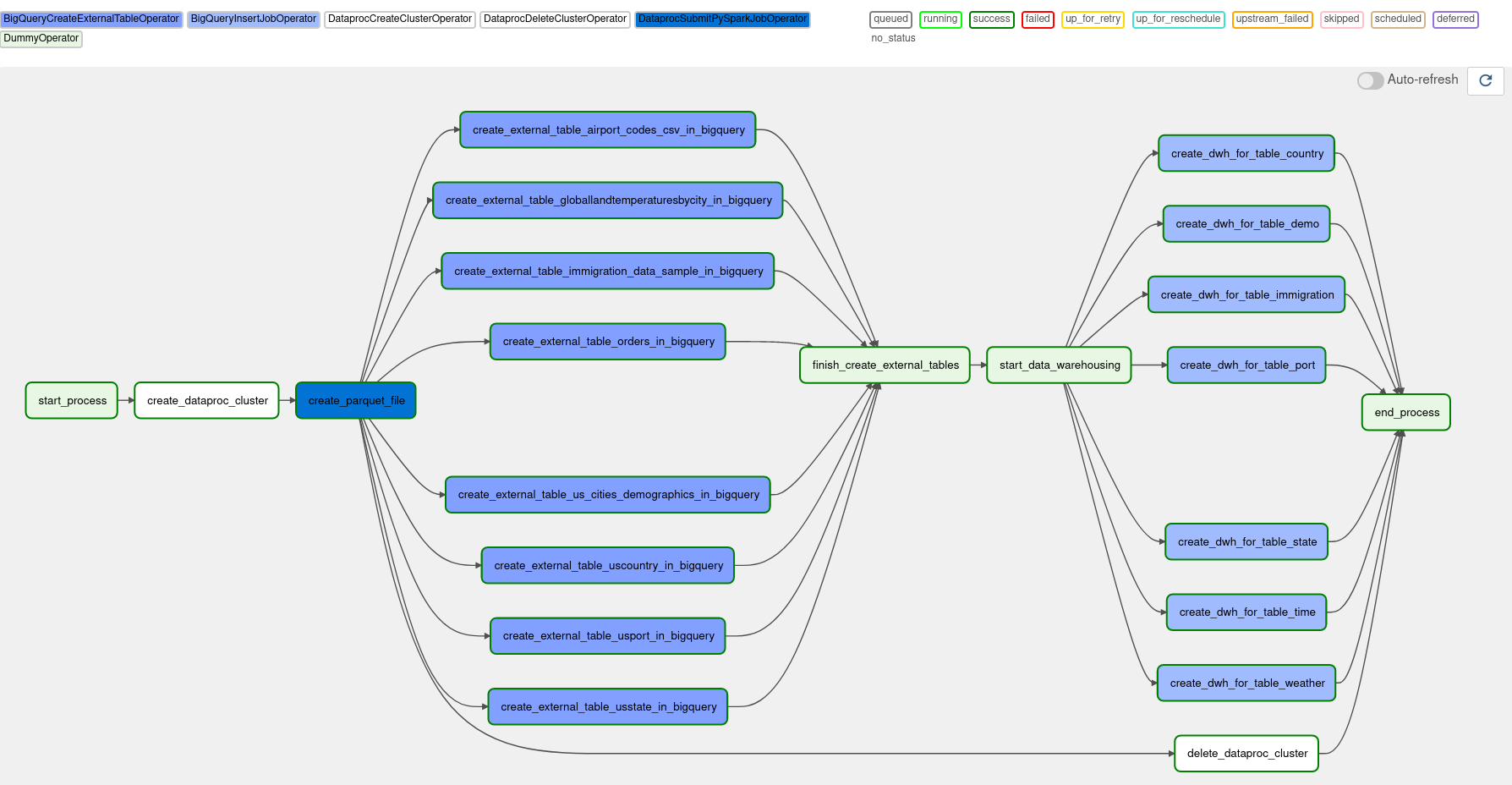
In the Airflow script, we need to import operators that will perform some tasks. Those operators are to create a Dataproc cluster, run a PySpark application, delete a Dataproc cluster, create an external table for BigQuery, and run a query on BigQuery itself to create a data warehouse table. In addition, there is an operator used to mark the start and end of a process.
To be specific, operators are listed in the table below.
| Function | Operator |
|---|---|
| marking | DummyOperator |
| create cluster | DataprocCreateClusterOperator |
| delete cluster | DataprocDeleteClusterOperator |
| run PySpark | DataprocSubmitPySparkJobOperator |
| create external table | BigQueryCreateExternalTableOperator |
| run query | BigQueryInsertJobOperator |
All definitions and usage details can be seen and learned in Apache Airflow Github repository. As we use Google Cloud Platform, most of the operators are located here.
The operators mentioned in the table above are based on Apache Airflow version 2.x.x. There are many differences when compared to the 1.x.x version, including the package name to be called in the script.
We make our graph like the image below.
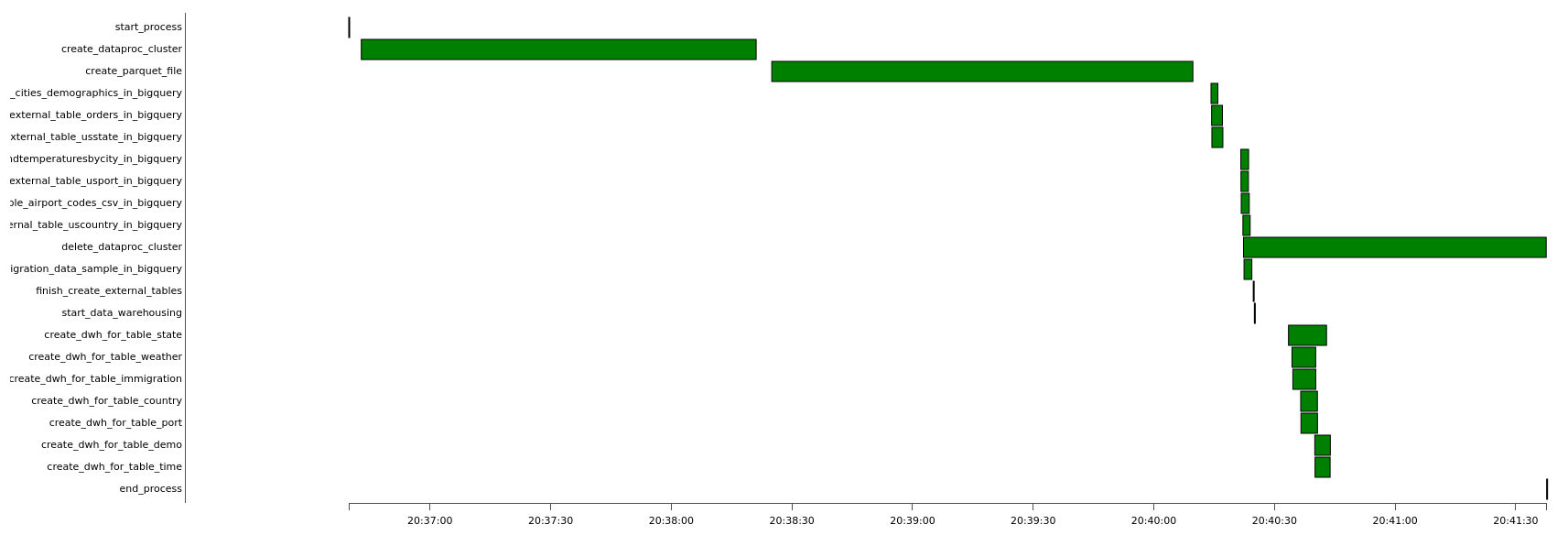
The duration of this dag to finish the execution is about five minutes. Long processes are at creating Dataproc cluster, running PySpark application, and deleting Dataproc cluster.
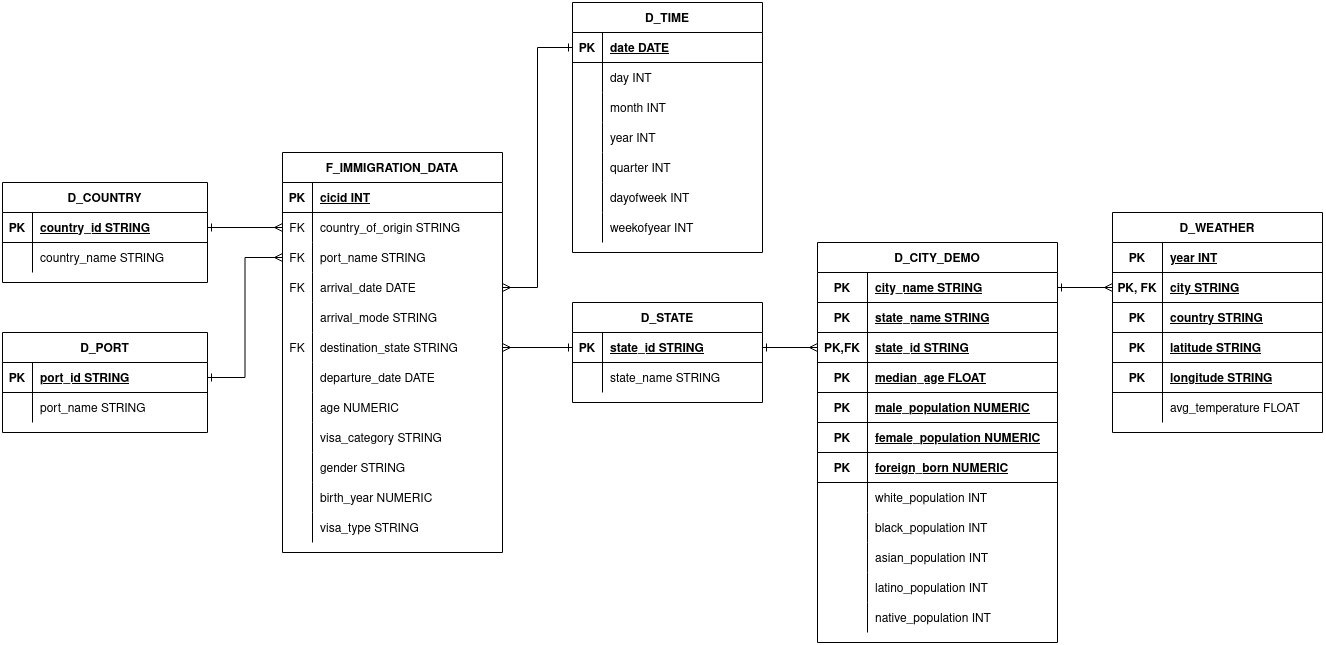
Entity Relationship Diagram
The relationship between tables in the data warehouse we created can be described in the ERD. We used this link to create the diagram.
Conclusion
This project implements the Extract, Load, and Transform (ELT) process of creating a data warehouse on the cloud. Skills acquired in this small project are:
- understanding about some Google Cloud Platform products.
- developing ELT pipeline by using Apache Airflow to create and delete a cluster in Google Dataproc, running a PySpark application, creating external tables, and running queries in Google BigQuery.
- reading, processing data, and writing files using Apache Spark to load raw files into a staging area.
- defining the relation between tables from a data warehouse which will be used by the user (e.g. data science and analytics teams).