Data Engineer Portfolio
Hi! I’m Thomas. I’m a Data Engineer. This page shows you all mini projects I made about data engineering. Some of them were built when I took an online class on data engineering from Digital Skola. I try to implement the knowledge I have by doing several projects that leverage any data engineering tools, like Python, Apache Spark, Apache Kafka, Apache Airflow, and many more.
Here are some project I made. Please click on the link in the project title which directs you to the appropriate Github repository and see more detailed explanations.
1. Creating an End-to-end Data Pipeline to Build Google BigQuery Data Warehouse
This is the final project from the online class I took from Digital Skola. The main idea of the project is creating a data pipeline to process raw files and create tables for a data warehouse. I played with Google Cloud Platform to run the pipeline.
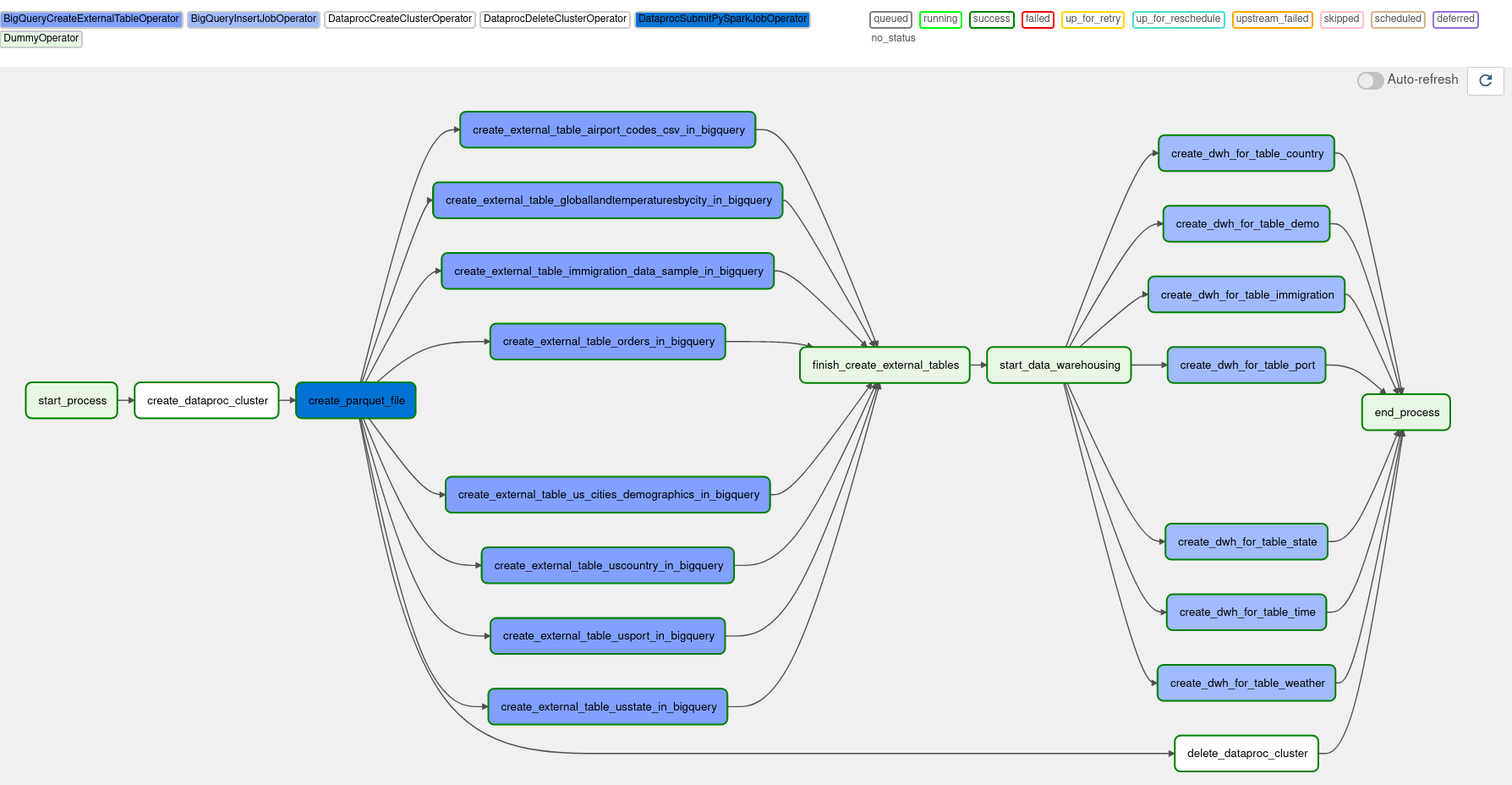
To be specific, the processes consist of these steps:
- Upload raw files to Google Cloud Storage.
- Create a Dataproc cluster to host Spark environment.
- Run a PySpark application to convert the raw files to Parquet.
- Load the Parquet files as external tables in Google BigQuery.
- Aggregate all necessary data from the external tables to create a data warehouse.
The steps are about ELT (Extract, Load, and Transform) process. In the Extract part, I uploaded the files into a storage bucket and convert to other format and save them also in the storage as a data lake. The files then loaded to BigQuery as external tables as the Load part. At last, the Transform part is aggregating the necessary data to make data warehouse.
To run the steps automatically, I used Apache Airflow as a workflow orchestrator which was provided by Google Composer. The workflow can be visualize like the image below.
2. Streaming ISS Position Data with Apache Kafka
This project contains two main part of tasks: streaming and consuming the data. I utilized Apache Kafka to stream data from an API that provides real time International Space Station position data. I also used Apache Spark to consume the data.
For the streaming part, I made a Python program that can be run in the shell with some configurations or arguments in order to set the amount of time the streaming will work. By default, it will never stop streaming.
The process is started by making a get request to the API every ten seconds, then creating a publisher using Kafka Producer to send the data into a Kafka cluster. I used Kafka Producer built for Python.
The next step is to create a consumer to get the data, which is made using Spark Structured Streaming as it is compatible to connect to a Kafka cluster. Spark Streaming has an ability to process the incoming data as well. The data is saved as CSV files and can be analyzed further. Again, I used PySpark to run the consumer.
3. Analyzing NYC Green Taxi Data with PySpark
The project is about analyzing green taxi data in New York City for year 2020. The data itself obtained from their website. I am using PySpark functionalities to clean the data, e.g. check any null values and give decision about all nonsense records. The cleaned dataset is saved to Parquet format.
I am also using Dash and Plotly to make a dashboard for the dataset so I can see the trends in 2020 interactively. The dashboard is available as a web application.
4. Scraping News using Scrapy Framework
The project is about getting information from a news portal. I am using Scrapy as a web scraping framework that can be utilized easily with Python as the programming language.